State of HTML 2023 now open!
tl;dr the brand new State of HTML survey is finally open!
Take State of HTML 2023 Survey
Benefits to you:
- Survey results are used by browsers to prioritize roadmaps — the reason Google is funding this. Time spent thoughtfully filling them out is an investment that can come back to you tenfold in the form of seeing features you care about implemented, browser incompatibilities being prioritized, and gaps in the platform being addressed.
- In addition to browsers, several standards groups are also using the results for prioritization and decision-making.
- Learn about new and upcoming features you may have missed; add features to your reading list and get a list of resources at the end!
- Get a personalized score and see how you compare to other respondents
- Learn about the latest trends in the ecosystem and what other developers are focusing on
While the survey will be open for 3 weeks, responses entered within the first 9 days (until October 1st) will have a much higher impact on the Web, as preliminary data will be used to inform Interop 2024 proposals.
![]()
The State of HTML logo, designed by Chris Kirk-Nielsen, who I think surpassed himself with this one!
Background
This is likely the most ambitious Devographics survey to date. For the past couple of months, I’ve been hard at work leading a small product team spread across three continents (2am to 8am became my second work shift 😅). We embarked on this mission with some uncertainty about whether there were enough features for a State of HTML survey, but quickly found ourselves with the opposite problem: there were too many, all with good reasons for inclusion! To help weigh the tradeoffs and decide what makes the cut we consulted both the developer community, as well as stakeholders across browsers, standards groups, community groups, and more.
We even designed new UI controls to facilitate collecting the types of complex data that were needed without making the questions too taxing, and did original UX research to validate them. Once the dust settles, I plan to write separate blog posts about some of these.
FAQ
Can I edit my responses?
Absolutely! Do not worry about filling it out perfectly in one go. If you create an account, you can edit your responses for the whole period the survey is open, and even split filling it out across multiple devices (e.g. start on your phone, then fill out some on your desktop, etc.) Even if you’re filling it out anonymously, you can still edit responses on your device for a while. You could even start anonymously and create an account later, and your responses will be preserved (the only issue is filling it out anonymously, then logging in with an existing account).
So, perhaps the call to action above should be…
Start State of HTML 2023 Survey
Why are there JS questions in an HTML survey?
For the same reason there are JS APIs in the HTML standard: many JS APIs are intrinsically related to HTML. We mainly included JS APIs in the following areas:
- APIs used to manipulate HTML dynamically (DOM, form validation, etc.)
- Web Components APIs, used to create custom HTML elements
- APIs used to create web apps that feel like native apps (e.g. Service Workers, Web App Manifest, etc.)
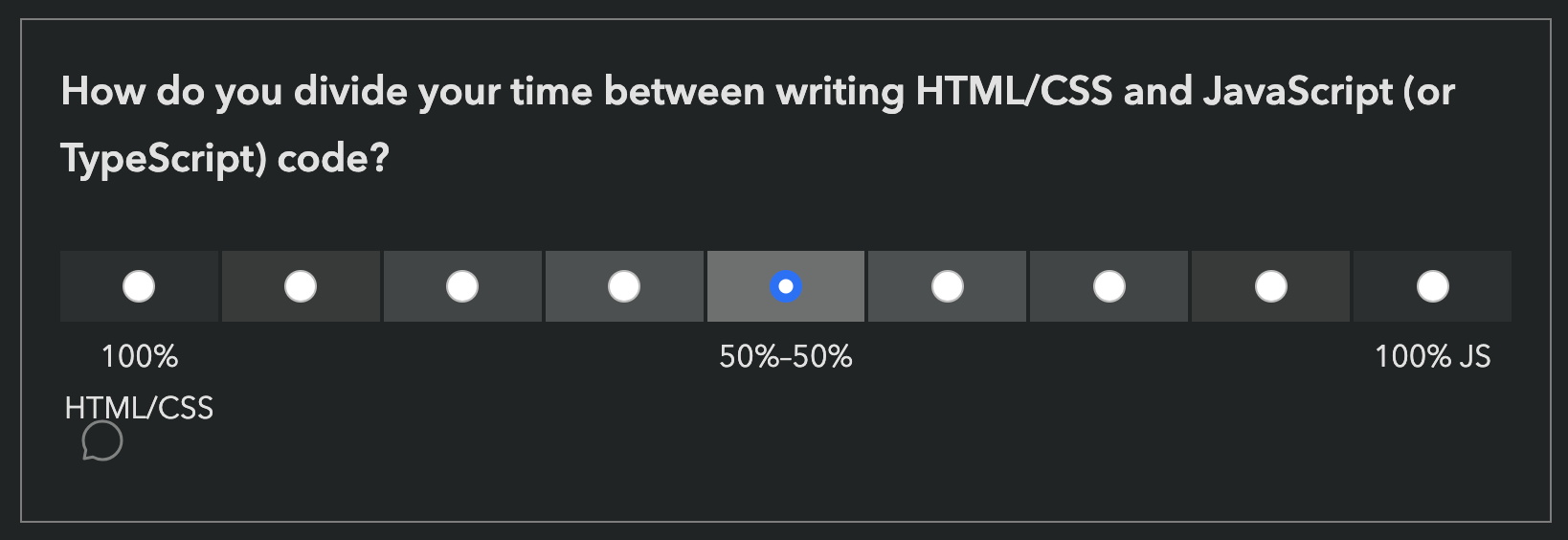
If you don’t write any JS, we absolutely still want to hear from you! In fact, I would encourage you even more strongly to fill out the survey: we need to hear from folks who don’t write JS, as they are often underrepresented. Please feel free to skip any JS-related questions (all questions are optional anyway) or select that you have never heard these features. There is a question at the end, where you can select that you only write HTML/CSS:
Is the survey only available in English?
Absolutely not! Localization has been an integral part of these surveys since the beginning. Fun fact: Nobody in the core State of HTML team is a native English speaker.

Each survey gets (at least partially) translated to over 30 languages.
However, since translations are a community effort, they are not necessarily complete, especially in the beginning. If you are a native speaker of a language that is not yet complete, please consider helping out!
What does my score mean?
Previous surveys reported score as a percentage: “You have heard or used X out of Y features mentioned in the survey”. This one did too at first:
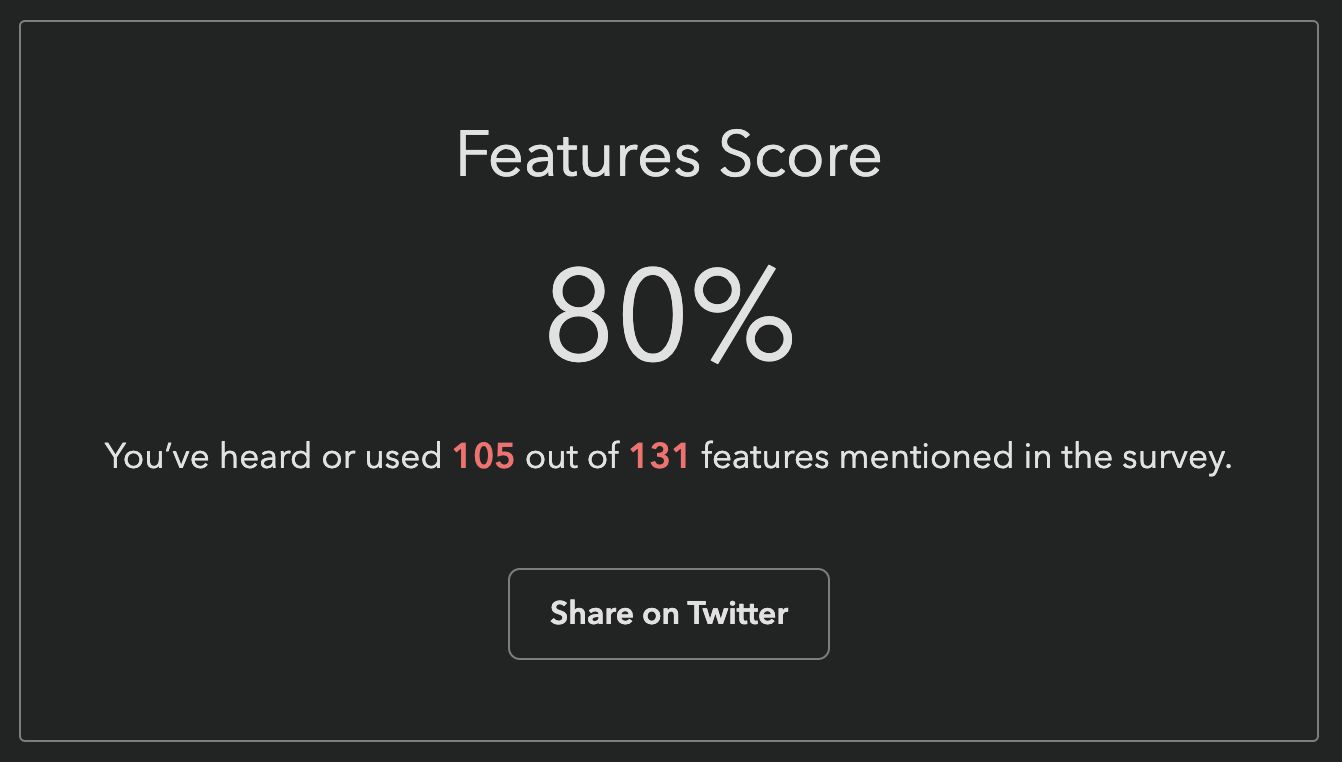
This was my own score when the survey first launched, and I created the darn survey 😅 Our engineer, Sacha who is also the founder of Devographics got 19%!
These were a lot lower for this survey, for two reasons:
- It asks about a lot of cutting edge features, more than the other surveys. As I mentioned above, we had a lot of difficult tradeoffs to make, and had to cut a ton of features that were otherwise a great fit. We err’ed on the side of more cutting edge features, as those are the areas the survey can help make the most difference in the ecosystem.
- To save on space, and be able to ask about more features, we used a new compact format for some of the more stable features, which only asks about usage, not awareness.
Here is an example from the first section of the survey (Forms):
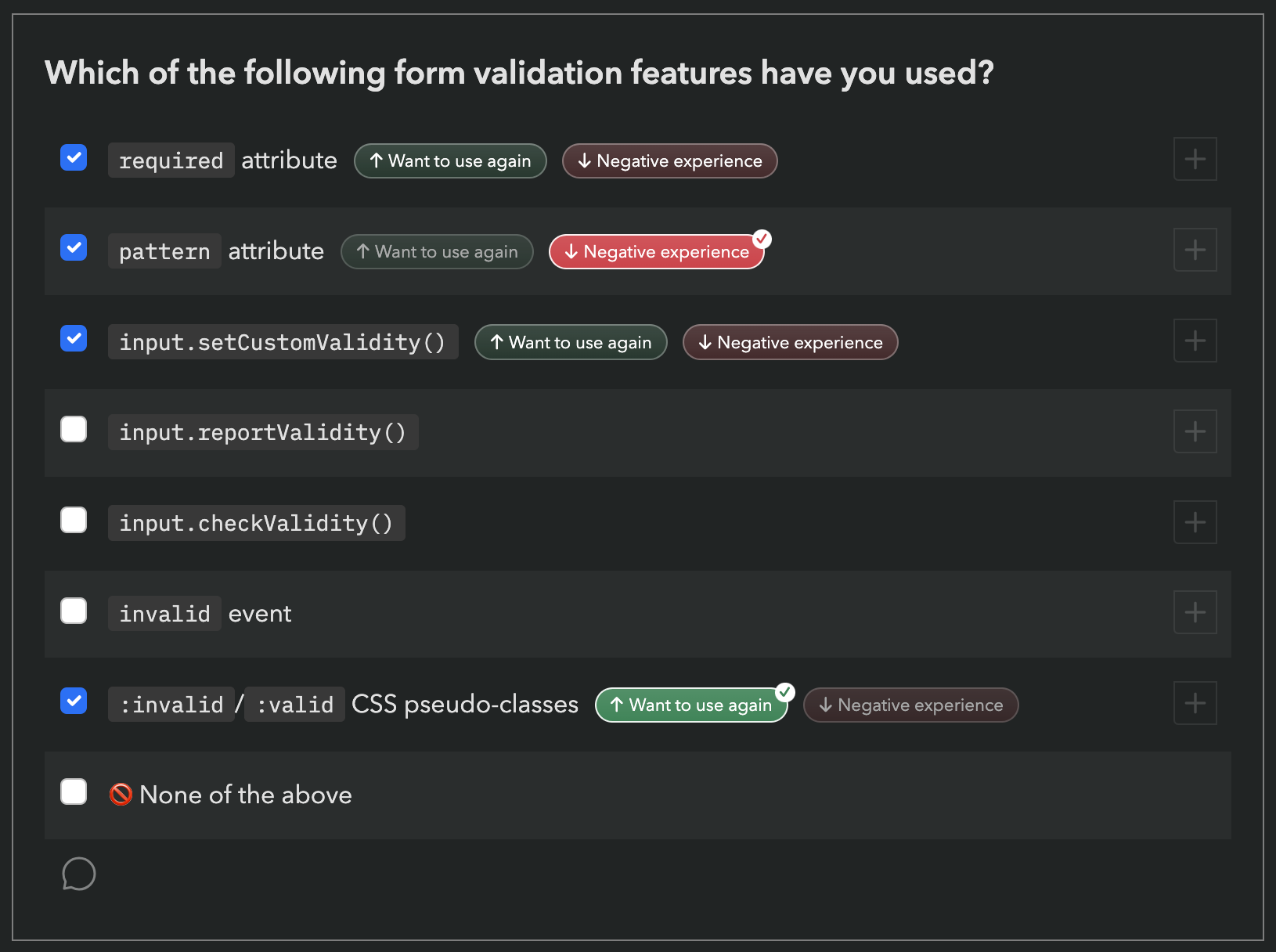 However, this means that if you have never used a feature, it does not count towards your score, even if you have been aware of it for years.
It therefore felt unfair to many to report that you’ve “heard or used” X% of features, when there was no way to express that you have heard 89 out of 131 of them!
However, this means that if you have never used a feature, it does not count towards your score, even if you have been aware of it for years.
It therefore felt unfair to many to report that you’ve “heard or used” X% of features, when there was no way to express that you have heard 89 out of 131 of them!
To address this, we changed the score to be a sum of points, a bit like a video game: each used feature is worth 10 points, each known feature is worth 5 points.
Since the new score is harder to interpret by itself and only makes sense in comparison to others, we also show your rank among other participants, to make this easier.
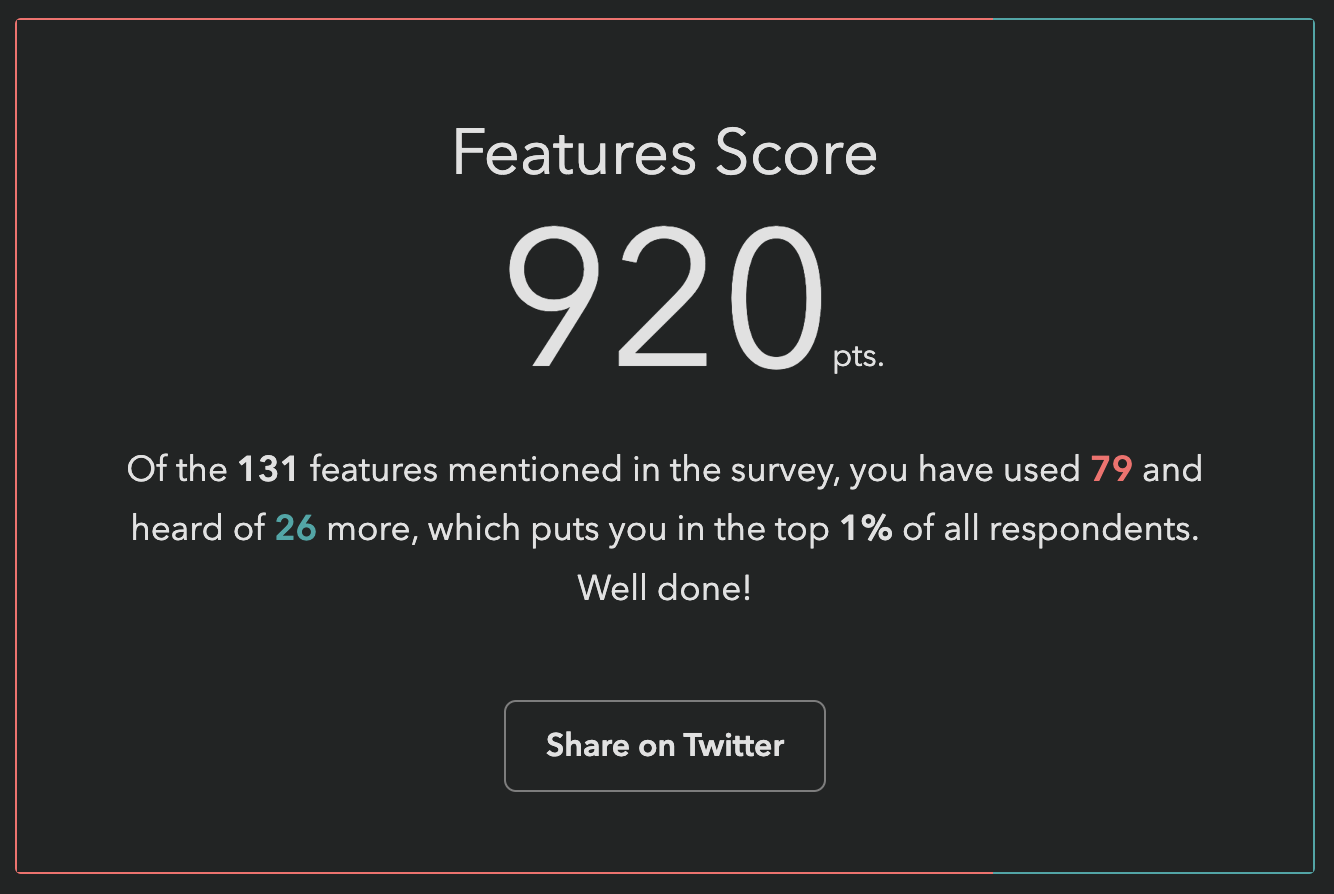
My score after the change. If you have already taken the survey, you can just revisit it (with the same device & browser if filled it in anonymously) and go straight to the finish page to see your new score and ranking!
I found a bug, what should I do?
Please file an issue so we can fix it!
Acknowledgements
This survey would not have been possible without the hard work of many people. Besides myself (Lea Verou), this includes the rest of the team:
- Engineering team: Sacha Greif, Eric Burel
- UX research & data science team: Shaine Rosewel Matala, Michael Quiapos, Gio Vernell Quiogue
- Our logo designer, Chris Kirk-Nielsen
And several volunteers:
- Léonie Watson for accessibility feedback
- Our usability testing participants
- …and all folks who provided early feedback throuhgout the process
Last but not least, Kadir Topal made the survey possible in the first place, by proposing it and securing funding from Google.
Thank you all! 🙏🏼
Press coverage (selected)
- Turns out I know less about HTML than I thought! 😅 - Kevin Powell (Video)
- Are you an HTML expert? Find out with the new State of HTML 2023 survey - dev.to
- Chris’ Corner: Things I Totally Didn’t Know About That I Learned From Taking the State of HTML 2023 Survey
- Frontend Focus
- CSS Weekly
- The HTML Blog


 I just dealt with one of the weirdest bugs and thought you may find it amusing too.
I just dealt with one of the weirdest bugs and thought you may find it amusing too.